Big Data

After having been accustomed to terms like MegaByte, GigaByte, and TerraByte, we must now prepare ourselves for a whole new vocabulary, such as PetaByte, ExaByte, and ZettaByte which will be as common as the aforementioned.
Dr Riza Berkan CEO and Board Member of Hakia provides a list of Mechanisms generating Big Data
- Data from scientific measurements and experiments (astronomy, physics, genetics, etc.)
- Peer to peer communication (text messaging, chat lines, digital phone calls)
- Broadcasting (News, blogs)
- Social Networking (Facebook, Twitter)
- Authorship (digital books, magazines, Web pages, images, videos)
- Administrative (enterprise or government documents, legal and financial records)
- Business (e-commerce, stock markets, business intelligence, marketing, advertising)
- Other
Dr Riza Berkan says Big Data can be a blessing and a curse.
He says that although there should be clear boundaries between data segments that belong to specific objectives, this very concept is misleading and can undermine potential opportunities. For example, scientists working on human genome data may improve their analysis if they could take the entire content (publications) on Medline (or Pubmed) and analyze it in conjunction with the human genome data. However, this requires natural language processing (semantic) technology combined with bioinformatics algorithms, which is an unusual coupling at best. Two different data segments in different formats, when combined, actually define a new “big data”. Now, add to that a 3rd data segment, such as the FBI’s DNA bank, or geneology.com and you’ll see the complications/opportunities can go on and on. This is where the mystery and the excitement resides with the concept of big data.
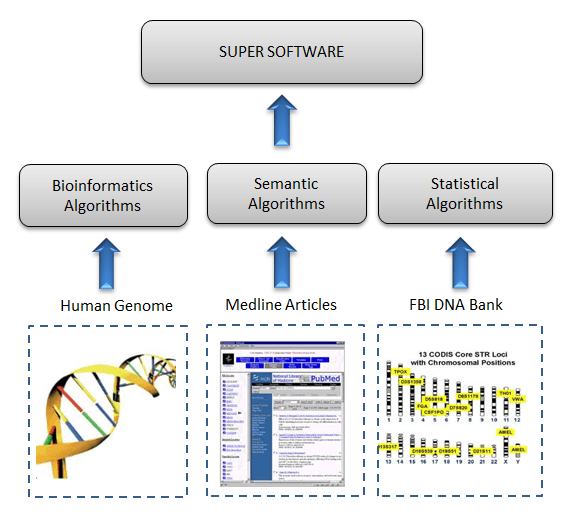
Dr Riza Berkan asks are we prepared for generating data at colossal volumes? and we should look at this question in two stages: (1) Platform and (2) Analytics “super” Software
Apache Hadoop’s open source software enables the distributed processing of large data sets across clusters of commodity servers, aka cloud computing. IBM’s Platform Symphony is another example of grid management suitable for a variety of distributed computing and big data analytics applications. Oracle, HP, SAP, and Software AG are very much in the game for this $10 billion industry. While these giants are offering variety of solutions for distributed computing platforms, there is still a huge void at the level of Analytics Super Software . Super Software’s main function would be to discover new knowledge which would otherwise be impossible to acquire via manual means says Dr Berkan.
Discovery requires the following functions:
- Finding associations across information in any format
- Visualization of associations
- Search
- Categorization, compacting, summarization
- Characterization of new data (where it fits)
- Alerting
- Cleaning (deleting unnecessary clogging information
Moreover, Dr Berkan says that” Super Software would be able to identify genetic patterns of a disease from human genome data, supported by clinical results reported in Medline, and further analyzed to unveil mutation possibilities using FBI’s DNA bank of millions of DNA information. One can extend the scope and meaning of top level objectives which is only limited by our imagination.”
Then too, Dr Berkan says big data can also be a curse if the cleaning (deleting) technologies are not considered as part of the Super Software operation. In his previous post, “information pollution”, he emphasized the danger of uncontrollable growth of information which is the invisible devil in information age.
credits: Search Engine Journal/SEG

